

Rethinking How We Build Python Applications
Insights and battle-tested patterns to help you move fast and stay in control as complexity grows.

Intro
Let’s start with an axiom, well-known to experienced engineers and somehow well-ignored by beginners.
Your job is not to write code. Your job is to solve problems through software, and coding is just one of the aspects.
When you start building a brand-new project, chances are your time and budget are fixed. If that’s the case, the only practical approach to get things done is the well-known FFF methodology: Fix time, Fix budget, Flex scope, originally formulated by 37signals in their bestseller Getting Real.
Having a well-coordinated team where each member knows their own limits and strengths (a rare thing in real life but still possible) such a team naturally strives toward the actual boundaries of FFF, where the first two Fs are constant basic requirements and the third one, the scope, is the best effort F.
How can we fit the most into this FFF trade-off from a technical perspective? By using a well-known set of efficient tools, combined with real experience and intuition, right?
Something that will help us reach the main goal: building a product on time, with fewer developers, less effort, lower costs, and as few errors as possible.
Programming is a bit like fashion — a constantly changing mix of overhyped technologies. How do we actually decide what’s worth using?
You either trust yourself, relying on your own professional experience, or you trust someone else who uses or promotes it. Maybe you even have your own favourite evangelist or influencer?
And, of course, last but not least, sometimes you’re simply forced to. There’s a good chance your company or team already has a standardised tech stack with no real reason to review it, and in most cases, you just use it as is. That’s not necessarily bad and there’s always a chance that the guy on the square-wheeled bicycle is actually you, not your stubborn teammate.
At the same time, we all need to periodically revisit the tools and approaches we use on a daily basis. We should be sceptical of all of them, because every tool was created by ordinary people solving their own problems, under specific conditions, in a particular historical context.
Maybe those people were simply wrong, selling us an idea that became widely adopted and still shapes our thinking years later. What if it was a popularised mistake? We must doubt.
That’s why good engineers constantly try out different new ideas.
That’s why open knowledge sharing is so important! It sparks innovation and supports personal growth.
That’s also why good team leaders encourage experimentation and the rotation of fresh ideas, while staying sceptical of all of them by default.
And you never know when the different fragments in your mind will suddenly begin to resonate, when the moment arrives and synthesis happens, and all the pieces of your interdisciplinary knowledge connect, creating a new mindset — your new Method.
Retrospective
I started my professional career as a Django web developer about 14 years ago, earning my first coding money by building websites in a tiny web studio located in a basement with no windows.
It was a time when Django and Python was nowhere near as popular as it is today. Most developers were into Ruby on Rails — the go-to web framework for startups back then. Ruby was sexy. Python was not.
Python had only a small share of the web development world compared to Ruby, PHP, and JavaScript at that time. But after trying a bit of everything, I became confident that Python was a more universal tool with greater potential.

14 years later, I still use Python as my primary language, even though it’s definitely not the best fit for everything. When you learn more different languages and paradigms, it becomes very clear.
Python is good enough, though. It allows you to move fast and its trade-offs are well balanced.

Back to Django. At the time, it seemed like a good idea to blindly follow the MVC pattern to build layered apps — or MVT, as Django prefers to call it. It felt natural.

Django itself encourages the MVT approach. And its fantastic ORM, full of dark magic. And signals. And fat models (or shall we call them abstract-positive)?
The thing is, Django was still quite new back then, and we didn’t have well-established practices for building complex systems that we could actually maintain later. And of course, we made plenty of design mistakes — spending days debugging here and there, sending emails directly from model classes, and doing many other barely legal things.
I recall a project where we literally trapped ourselves. Everything was so ugly under the hood, and so slow on the surface, that we ended up using aggressive Redis caching almost everywhere, with signal-based invalidation of course and constantly dying Celery workers rebuilding our heavy search indexes.
You may think that we simply didn’t have enough expertise to build anything more complex than blogs — and you would be right. Of course we didn’t.
Years later, now that I have more practical experience and have learned better practices, it’s very clear what went wrong and when. MVT, first of all. It doesn’t scale well. And...
class ListBaseView(
QueryMixin,
PaginationMixin,
TemplateNameMixin,
JsonResponseMixin,
BaseView,
):
"""
Generic list view with way too many responsibilities.
"""
def get(self, request, *args, **kwargs):
qs = self.get_queryset()
context = self.get_context_data(objects=qs)
return self.render_to_response(context)
Django introduced class-based views, or CBVs, in version 1.3 — and everyone happily started to overuse them in their projects. That whole idea of multi-inheritance mixins seemed brilliant at first, but it turned out to be one of the worst decisions ever made in web development history. It’s still one of my favourite examples of a long-running mistake with awful consequences.
The most treacherous metaphors are the ones that seem to work for a time, because they can keep more powerful insights from bubbling up.
— Alan Kay.
We abused inheritance over composition, and our app became as “flexible” as Python itself. We had clearly sunk into a bog of leaking abstractions, and we spent our days debugging where all that crap was coming from.
At some point, you’re fighting the tool instead of leveraging its strengths.
Then Pyramid happened to me, the "wire everything yourself" web-framework — one step closer to micro-frameworks and real modular app design.

Pyramid definitely deserved more attention, but it was too flexible and too verbose. Sitting somewhere between Django and Flask, it was always a hard sell.
Somehow it happened, there was a marketplace project — a really big one, built with Pyramid. And I was lucky enough to see what a truly large and complex Python web application can look like.
Teams used every trick in the book to keep the whole thing afloat. It was phenomenal! I’m still impressed that it actually worked. From the architecture perspective It was, let’s call it, an “opinionated variation” of MVC. To add a new feature, you had to dive into all the nuances of every single layer, spreading it across the codebase — jumping from package to package like a grasshopper.
And there were Mako templates. A lot of them. Many hundreds. If you’ve ever worked with Mako, you know they’re not bad, they’re just too permissive. You can call almost any Python code from a template, which can easily lead to accidental API calls or extra database queries that are very hard to track down.
<%! from myapp.services import get_discount_for_product %>
% for p in products:
<div class="product-card">
<h2>${p.name}</h2>
## more queries and API calls, why not?
<% discount = get_discount_for_product(p.id) %>
% if discount:
<p><strong>${discount}% off!</strong></p>
% endif
</div>
% endfor
Of course, that’s a huge antipattern. Everyone agreed it was bad, and we had endless discussions about logicless templates and better practices.
But the “broken windows theory” works well here. As a developer, you open a template, see all the mess and piles of logic inside, and you just need to add one tiny thing. To do it properly, you’d have to refactor the entire template inheritance tree and the underlying controllers — but the deadline was yesterday, as usual. So you close your eyes… and just do it.
I started to suspect that application architecture might actually be important. Maybe we should invest more time and effort in learning better ways to organise code?
You can easily google different well-known approaches for that, like Clean Architecture, Onion Architecture, and Hexagonal Architecture. They are essentially all the same: keep your core logic pure and push all the messy, changing stuff (databases, frameworks, APIs) to the edges. That’s it.
And there are also communication-centric architectures: Event-Driven Architecture, Service-Oriented Architecture, Actor Model, etc. These define interaction patterns between systems or services.
Perfectly splendid. But the suggested abstractions and tools were, well, too abstract to understand and barely seemed applicable to my day-to-day problems. And the metaphors — too heavy and never really clicked for me, even today.
I mean, look at that! What the heck is this supposed to be? A nuclear reactor blueprint?
The thing is, I believe Python and its ecosystem were never really seen as something worthy of enterprise attention. Not mature enough. Not for “serious business”. It was viewed more as a “startup” or “prototype” language. Most practical examples you could find back then were written with Java or .NET in mind, never in Python.
Naturally, you thought: That’s not how we do things here. It’s not Pythonic — too verbose, too complex, too many abstractions, it just doesn’t feel right. Good “Pythonic” examples were out of reach. If they even existed.
Then Tornado happened to me. I found myself in a brand-new world of asynchronous programming and a pretty niche framework at that time. It was fresh, it was cool, it was fast. And it was a first true micro framework, with no predefined layout or boundaries at all.

That was the time of the boldest experiments in my dev career. I can definitely say I learned a lot. I was actively researching, trying to find that elegant, simple, scalable, modular, well-testable, Pythonic way to build apps. Web apps first of all, but any apps essentially.
It reminds me of the story of chemistry as a young science — full of preconceptions. While alchemists were searching for the philosopher’s stone and failing, of course, they were also discovering the useful properties of substances and how to work with them, gradually crystallising real methodologies and facts about nature.
Nothing personal. Just business.
Always start with business requirements!
It's an almost self-evident idea. Before any coding rush, we need to understand the business problem correctly.
Let’s imagine our requirement is to build a video-on-demand platform for professional creators, where they can easily monetise their work. Creators upload their content, set prices and preferences, and share it directly with their audience. Viewers pay for what they watch, supporting their favourite creators. Simple as that.

It looks like we have two basic user roles here: a viewer and a creator. We debit the viewer when they watch a video and credit the creator when the video is viewed.
But running an actual card transaction for every single playback would be inefficient for many reasons, so we need some kind of internal credit system that viewers can use to redeem content.
In Hypha, these are called Points — they come in Packs that users can purchase to top up their accounts. Naturally, we need ledgers to track balances, reconciliation with our payment vendor, and payouts for creators. So yes, we definitely need billing here.
As a stakeholder, I’d like to see a rental-based and tips-based creator economy, offering day, month, or lifetime access, with optional tips — implemented as a smooth, single-click video unlock experience.

And so on, and so on. We keep collecting business requirements.
To translate these business needs into something we can actually discuss with the team and build, we need a shared, ubiquitous language so everyone talks about the same things in the same way.
This is what Domain-Driven Design (DDD) is all about.
DDD 101
In short, DDD ensures the code speaks the same language as the business — shared terms, clear boundaries, and models that reflect how things actually work.
Your first instinct might be to think about your system in terms of SQL tables and the relationships between them.

Don’t do that. How you store and persist your data should never dictate your application design or your domain model!
The same goes for OOP. As a developer, you might immediately start creating classes and factories in your head, translating business requirements directly into a tree of classes.

Then something like AbstractBaseVideo class appears. And that already means nothing — it’s just an implementation detail, and probably not even a good one. Don’t do that.
Core building blocks of DDD are Domain and Bounded Context.
The domain is the area of knowledge or activity your software is built to serve — the business problem you’re solving. For our video platform, the domain includes things like: Videos, Users, Analytics, Billing, etc.
The domain also defines the rules — how these parts interact, what’s allowed and what isn’t. For example, who can upload or access a video, what its lifecycle looks like, how payouts are calculated? These rules are the core of the system’s logic — that’s what defines the product.
Each major part of that world can be its own bounded context, with its own rules and data model. Why bounded contexts matter?
As your system grows, words like Video, User, or Payment start to mean different things in different parts of the system.
In Content Management, a Video is a media asset with files and metadata.
In Analytics, a Video is a source of metrics — views, retention, engagement.
In Billing, a Video is something that generates revenue.
If you try to use one single model for all of those meanings, you end up with entangled codebase, endless conditionals and special cases.
Then come Entities and Value Objects. These are the building blocks of your domain model.
Entity – an object with a unique identity that persists over time (e.g. User, Video).
Value Object – a small, immutable object that represents a concept by its value, not by identity. In the case of a Video, it can be a video track, audio track, subtitle track, or image sprite, each with its own metadata.
In DDD, you group related entities and value objects into Aggregates — clusters of objects that change together and are treated as a single unit for data updates and consistency.

Here you can see a simplified example of a real Video aggregate, where Video is the root entity — also known as the Aggregate Root — and attributes like SourceMeta, Playlists, CoverImage, and a few others are Value Objects, assembled together into one cohesive unit.
@dataclass(kw_only=True)
class Video:
id: UUID = field(default_factory=uuid7)
public_id: NanoID = field(default_factory=generate_nano_id)
owner_id: HyphaID
title: str | None = None
description: str | None = None
src_meta: SourceMeta | None = None
playlist: VideoPlaylist | None = None
video_tracks: list[VideoPlaylist] = field(default_factory=list)
audio_tracks: list[AudioPlaylist] = field(default_factory=list)
subtitle_tracks: list[VideoSubtitle] = field(default_factory=list)
cover_image: CoverImage | None = None
fallback_cover_image: CoverImage | None = None
state: VideoState
created_at: DateTime = field(default_factory=now)
updated_at: DateTime = field(default_factory=now)
@classmethod
def build(cls, owner_id: HyphaID, state: VideoState = VideoState.INIT) -> Self:
fsm = FSM(transition_map=TRANSITION_MAP, initial_state=state)
return cls(owner_id=owner_id, state=VideoState(fsm.current_state))
How do we interact with an aggregate? Through a Repository, of course.

Repositories are mediating between the domain and the data-mapping layers, providing a stable, predictable interface for accessing and persisting aggregates.
In coding terms, define a repository as a Protocol that specifies a contract. The actual implementation comes later.
class VideoRepository(Protocol):
db: Database
async def add(self, video: Video, connection: Connection | None = None) -> None: ...
async def update(self, video: Video, connection: Connection | None = None) -> None: ...
async def get_by_id(
self,
*,
video_id: NanoID,
states: list[VideoState] | None = None,
owner_id: HyphaID | None = None,
connection: Connection | None = None,
) -> Video | None: ...
A valid repository has a few clear signs:
Operates on aggregates, not on arbitrary entities.
There is one repository per aggregate root.
Returns fully built aggregates, not partial data structures.
Next come the Services. And there are two types.
A Domain Service:
Encapsulates domain logic that spans multiple aggregates.
Operates purely within the domain layer (no I/O, databases, or API calls).
It is stateless.
While Domain Services define what the business does, Application Services define when and how it happens. They handle:
I/O (calling repositories, sending events, triggering workflows)
Transactions and orchestration
Integration with external systems
Rule of thumb: if it can be unit-tested, it’s a domain service. If not, it’s an application service.
Just like with repositories, you start shaping your service with a protocol first.
class VideoPreferenceService(Protocol):
async def get_favourites(
self,
*,
owner_id: HyphaID,
limit: int = 12,
offset: int = 0,
connection: Connection | None = None,
) -> list[Video]: ...
async def get_picks(
self,
*,
owner_id: HyphaID,
limit: int = 12,
offset: int = 0,
connection: Connection | None = None,
) -> list[Video]: ...
Keep I/O at edges to reduce side effects
There’s input and there’s output.
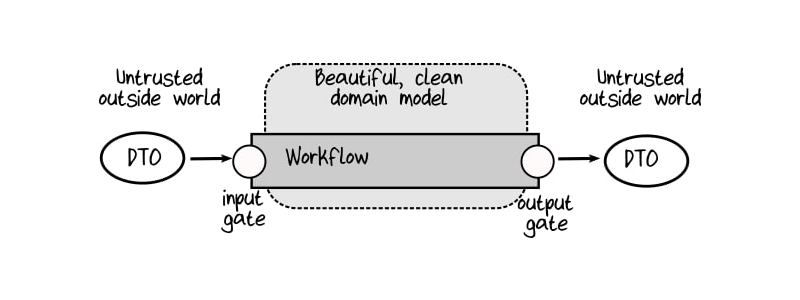
Your domain in between should remain clean — pure business logic with no side effects.
All data is validated at the edges, and everything inside should be as immutable as possible.
Use DTOs (Data Transfer Objects) on the boundaries to serialise and deserialise data between layers or systems. A DTO is just a simple data container, it’s not supposed to contain any business logic, just validated, serialisable data.
Sounds like Pydantic, right? Many developers abuse Pydantic models, using them for everything, including domain modelling. Don’t do that. Keep your Pydantic schemas at the edges for requests and responses, but never inside your domain.
Inside, prefer plain dataclasses — simple and framework-agnostic.
Data flow must be one-way
No layer should depend on or call a layer that depends on it. Data and control must flow in one direction — forward, from input to output.
Every deterministic application, no matter how complex, follows the same basic pattern:
$$I → System → O$$
It's a data-transforming Pipeline.
In Hypha, pipelines control the entire video lifecycle, including all transcoding processes.
pipeline = (
ConvertingInitial(inputs={"video_id": video_id})
>> ConvertSubtitles()
>> ConvertBaseAudio()
>> ConvertVideoTo480p()
>> RenderFinalPlaylist()
>> ImportKeys()
>> PublishToIPFS()
>> ConvertingTerminal()
)
result = await executor.run(pipeline)
A Pipeline consists of logical Units that are designed to be composed from left to right. We don’t need to go through all the implementation details now. What’s important is that this approach lets you express even the most complex logic in a linear, readable flow you can hold in your head.
Technically, everything can be a pipeline. But the recommended convention is: if Aggregates assemble Entities and Value objects, and Repositories sit on top of Aggregates, and Services sit on top of the Domain and I/O, then Pipelines sit above all of that.
SoC + LoB = ❤️
Everyone has heard about Separation of Concerns. There’s also a lesser-known concept called Locality of Behaviour — and it’s important to note that these two are not mutually exclusive.
Separation of Concerns means dividing a system into distinct parts, each responsible for a single purpose. Each layer or component should focus on one thing.
SoC isn’t about technology boundaries — it’s about responsibility boundaries.
Locality of Behaviour means keeping all code for one behaviour in one place. You should be able to remove it, disable it, or replace it easily. It reduces context switching and is one of the key principles to keep in mind.
In short: a feature’s behaviour should be local. You shouldn’t have to jump across the whole codebase to understand or change it.
Practically speaking, instead of:
/models/order.py
/endpoints/order.py
/templates/order_detail.html
/services/payment.py
You should prefer this:
/orders/
models.py
service.py
endpoints.py
templates/detail.html
Identify moving parts
Your domain layer should never depend directly on moving parts, because that makes it fragile. When a moving part changes, you don’t want your entire domain to break.
The database is a moving part. It can change — its schema, technology, connection details.
Your HTTP client in a service is a moving part. Your standard logger is a moving part — you can replace it with something like Loguru, for example. Even your web framework is a moving part. Ideally, your entire business domain layer should stay untouched when you change frameworks.
Because a web framework is I/O — and I/O is always a moving part.
Connecting dots
Okay, finally we have all the puzzle pieces. Now we need something to wire them together. That’s where a so-called Injector comes in.
Instead of our objects constructing their dependencies, we construct them from the outside and pass prepared arguments into their constructors.
Dependency Injection isn’t a standard approach in Python, and many developers don’t even realise they’re using it — but they actually do.
pytest has its own form of DI for fixtures and tests.
@pytest.fixture
async def test_client(test_app: FastAPI) -> AsyncGenerator[AsyncClient]:
async with AsyncClient(
transport=ASGITransport(app=test_app),
base_url="http://testserver",
) as client:
yield client
# the test_client fixture can be injected into a test now
@pytest.mark.asyncio
async def test_landing_page_anon(test_client: AsyncClient) -> None:
response = await test_client.get("/")
assert response.status_code == 200
FastAPI, the most popular Python web framework today, has its own DI system. In fact, FastAPI has done a great job of popularising dependency injection in the Python community!
@router.get("/", response_class=HTMLResponse, dependencies=[Depends(require_anon_user)])
async def index(
request: Request,
jinja: Annotated[Jinja2Templates, Depends(get_jinja_env)],
video_repo: Annotated[VideoRepository, Depends(get_video_repo)],
settings: Annotated[Settings, Depends(get_settings)],
) -> HTMLResponse:
...
return jinja.TemplateResponse(
request=request,
name="pages/welcome.html",
context=context,
)
However, FastAPI’s injector is scoped only to the request–response lifecycle, and it’s tightly bound to the framework — a moving part. That means you can’t reuse it inside your Domain anyway.
Lucky us, there’s a simple, lightweight, framework-agnostic solution called Injector.
An Injector is a wiring tool that connects Ports (your protocols) with Adapters (their concrete implementations), forming a central registry of application dependencies.
class CoreModule(Module):
@singleton
@provider
def provide_config(self) -> Settings:
return Settings()
@singleton
@provider
def provide_db(self, settings: Settings, logger: Logger) -> Database:
return Database(db_uri=str(settings.postgres.pg_dsn), logger=logger)
class ContentModule(Module):
@provider
def provide_video_repo(self, db: Database) -> VideoRepository: # protocol
return VideoRepositoryAdapter(db=db) # a protocol-compliant implementation
@provider
def provide_email_service(
self,
settings: Settings,
logger: Logger,
) -> EmailService:
if settings.environment == Environment.TEST:
return EmailServiceStub(settings=settings, logger=logger)
else:
return EmailServiceAdapter(settings=settings, logger=logger)
injector = Injector(
modules=[
CoreModule,
ContentModule,
]
)
Dependencies can also depend on each other. For example, VideoRepository might require a db object, which is just another dependency defined in the same injector.
In practice, you can have dozens of repositories and application services registered and configured this way.
class VideoRepository(Protocol):
db: Database
async def add(self, video: Video, connection: Connection | None = None) -> None: ...
@inject
class VideoRepositoryAdapter:
def __init__(self, db: Database):
self.db = db
async def add(self, video: Video, connection: Connection | None = None) -> None:
if connection:
await self._add(video, connection=connection)
else:
async with self.db.pool.acquire() as conn, conn.transaction():
await self._add(video, connection=conn)
Notice the @inject decorator here — it marks a class so that the injector will automatically provide its dependencies when it’s created or called. Now, whenever you need a video repository, you can simply call video_repo = injector.get(VideoRepository), where VideoRepository is the protocol and video_repo is the concrete instance provided by the injector.
A useful side effect worth mentioning. The PublishTileConsumer class here isn’t a dependency and isn’t part of the injector configuration. But since all the attributes in its constructor are already known to the injector, the injection just works automagically. Handy!
@inject
class PublishTileConsumer(SSEConsumer):
def __init__(
self,
db: Database,
profile_repo: ProfileRepository,
video_repo: VideoRepository,
settings: Settings,
logger: Logger,
):
self.video_repo = video_repo
self.profile_repo = profile_repo
self.settings = settings
self.logger = logger
self.db = db
async def process(self, event: StreamVideoEventPayloadSchema) -> list[SSEEvent]:
...
DI is a great pattern, but we end up with three different DI systems! And if you want to reach the app’s dependencies inside FastAPI, you basically have to wrap one injector inside another.
@asynccontextmanager
async def lifespan(app: FastAPI) -> AsyncGenerator[None]:
injector: Injector = app.state.injector
db = injector.get(Database)
async with db:
yield
app = FastAPI(lifespan=lifespan)
app.state.injector = injector # our app-wide injector
def get_injector(request: Request) -> Injector:
return cast(Injector, request.app.state.injector) # YEP!
def get_video_repo(
injector: Annotated[Injector, Depends(get_injector)],
) -> VideoRepository:
return injector.get(VideoRepository)
@router.get("/me")
async def dashboard_page(
request: Request,
video_repo: Annotated[VideoRepository, Depends(get_video_repo)],
) -> HTMLResponse:
....
Maybe one day we’ll see a proposal for a standard injector in Python, similar to Java’s JSR-330 dependency injection specification. Who knows?
And that’s it!
This is it! That’s Hexagonal Architecture (aka Ports & Adapters) with Dependency Injection, implemented in Python.
By following these simple, straightforward principles, you can gradually scale the complexity of your application without degrading code quality, maintaining a clean design and well-testable components.
Speaking of tests. Here’s a bonus observation.
If you have to use mocks in your tests — your code smells.
Literally. If you find yourself relying on mocks, magic mocks, or anything similar, your composition is wrong. With proper Ports & Adapters, you never need mocks. Just implement simple stubs that follow the protocol and register them as substitute implementations for your test environment via the injector.
Speaking of FastAPI — it’s just great. The author, the community, the documentation, and its close collaboration with the Pydantic team are all excellent. FastAPI is King for a reason and it deserves that title.

And of course, use the modern Python toolset:
uv as your default package/runtime tool
ruff for linting
mypy for type checking
httpx as your default async HTTP client
Solid defaults for your pyproject.toml in 2026.


